

SQL Saturday Colorado Springs (SQLSat #584)
It’s been a while since I’ve attended a SQL Saturday. I think the last one was in 2013 in OKC, to be exact. I had blogged about that one too, but I think I lost that post with the old website. At any rate, it was great to be able to go again. It’s an excellent opportunity to be able to catch up with what’s going on in the SQL community. It also aligns with my goal for the year to focus more on development. Although being the introvert that I am, meeting people is still a difficult task.
I attended three-morning sessions and two-afternoon sessions, including the one Steve Jones was putting on about DevOps. The DevOps session was the main reason I decided to go. The snow the day before made me question whether I should attend or not, but I decided it was worth the chance.
Here are the sessions I attended:
Stats and Cardinality Estimator
Susantha Bathige (blog/twitter) started things off with a discussion about the new cardinality estimator (circa SQL 2014) and then a discussion about statistics. I’m being honest, here, this was a bit of an in-depth session on a topic that I’m not up to speed on, this is an area I need to work on. It ended up being a little too technical, too early. While I picked up on some of it, most of the discussion went over my head.
Visualize your Transaction log
Brian Hansen (blog/twitter) gave an excellent session on the fundamentals of the transaction log. It was a beginner course, and much of this, I already knew. He did get into the basics of VLFs, which was a good primer for the later course on VLFs for the last session. I was torn about going to this session vs. the advanced session on AG troubleshooting. As I mentioned, though, I wanted a primer for the afternoon session on VLFs.
Bringing DevOps to the Database
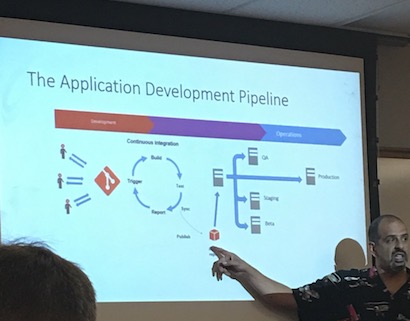
Steve Jones (blog/twitter) offered a great session on DevOps and version control for database people. I wanted to attend this session, as I think it’s something we could use/implement at work. As I suspected, it was worth the trip. I walked out with some ideas on how to both use this at work and help with my transition to database development. Now I just need to learn how to use versioning control software.

Accelerating DevOps and TDM using Data Virtualization
Tim Gormon (twitter) talked about thin provisioning databases using a hardware appliance. IT’s a fascinating concept, and I can see the benefit. Hell, I wish we had something like this now. The idea that we can thin provision our databases to ease storage costs and not endure the bloat of test/dev systems is fantastic. My question is, while I have no doubt this will be the norm eventually, is this something most shops can afford now?
Get into the Goldilocks zone: Managing SQL Transaction Log VLF Growth

Michelle Poolet (twitter) Talked about managing transaction logs and the VLFs that go with the transaction log. She provided great information about the algorithms, including some hard numbers. I’m glad I went, but at the same time, this wasn’t the session I was hoping it would be. I didn’t find any great revelations from this session like I thought I would. I seemed to have learned much more about the subject than I realized. One of the points she did make was to adjust the tlog auto grow settings instead of using defaults, pre-size them, and pre-size the auto grow increment. Good Advice!
Overall
It was a great day of learning and hanging out. For the most part, there was plenty of room; there was only one session that ran out of seats. I noticed there were quite a few people wearing smartwatches and Fitbits. Which I think is excellent, I think we spend too much time sitting. Of course, it could just be that these people are data nerds and like to measure stuff. I wish the ability to stand during these sessions was a little more conducive to using a laptop. I’m personally trying to move more and sit less. Although I won’t complain too much, I did win the SQL Toolbelt from Redgate’s raffle.